Why Qubit Count Is Not Everything
The qubit is often portrayed as the fundamental unit of information in a quantum computer. This seems natural, since in ordinary classical computers, information is always represented in bits and bytes – sequences of 0s and 1s. And therefore, bits and bytes are often used to measure everything from processor architecture (32-bit or 64-bit) to hard drive size (terabytes) to network speeds (gigabits per second).
And so, as companies have begun to develop early-stage quantum computers, nearly always the first attribute reported is the number of qubits that the device contains. 5 qubits. 10 qubits. 19 qubits. 72 qubits.
But wait – what does it mean to say that a quantum computer “has” 72 qubits? Should we think of this in terms of the “bitness” of processor architecture – as the amount of information that can be processed at once? Or is this somehow a quantum memory, and 72 qubits is the information storage capacity of the device? But either way, a quantum computer with 72 qubits must be far superior to one with 10 qubits, right? Answering these questions requires a better understanding of what a qubit actually is.
What is a qubit?
If you ask this question to someone knowledgeable, you’ll usually get some version of the following answer: “An ordinary bit can have a value of either 0 or 1, but a qubit can have a value that is any arbitrary superposition of 0 and 1.” Or, you’ll be shown a picture of a sphere, with 0 at the top and 1 at the bottom, and you’ll be told that a qubit can represent any point on the surface of that sphere. So for a qubit, there are not just two possible values, but infinitely many possible values! So of course quantum computers are more powerful!
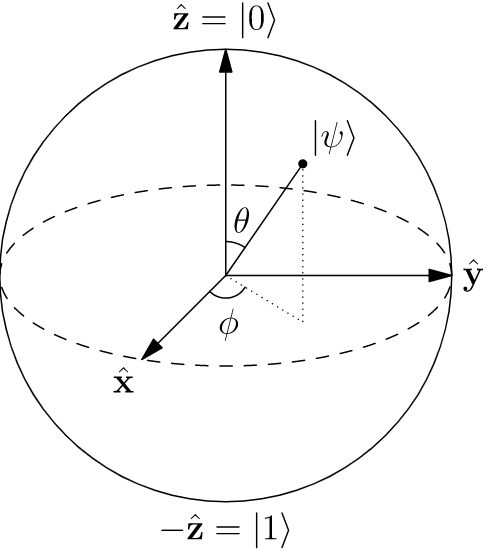
That’s fine, and it’s a mathematically accurate description, but it does very little to help us understand conceptually how these “qubits” can help us. In fact, without some background in quantum physics, it can even be a little misleading. If one qubit has infinitely many possible values, doesn’t that mean we could just encode an arbitrarily large amount of information and store it inside a single qubit?
The key physical principle to understand here – and one of the things that really constrains how we can build a quantum computer, and how powerful they can be – is that when you try to read the value of a qubit, you will always either get a 0 or 1, and the value of the qubit itself also immediately “collapses” to 0 or 1. The information about the delicate superposition you encoded is completely lost. (This is an example of a paradox in quantum physics known as the measurement problem – the simple act of looking at the qubit actually changes its state!) So in other words, if you tried to encode the full-length Titanic movie into the state of one of your qubits, when you try to play it back, you’ll be sorely disappointed (or greatly relieved, depending on your feelings about the movie).
Ok, so if we have a 72-qubit quantum computer, and when we read those qubits we can get only 72 bits of information out, that doesn’t sound very exciting. Where’s the power of quantum computing? Well, the measurement problem only applies if we look at the qubits! So, obviously, we need to make things happen while we’re not looking. In other words, the qubits need to interact with one another directly.
Neighborly qubits
From the discussion above, it is hopefully clear that we shouldn’t use the number of qubits as the primary measure of quantum computing power. Instead, the power of quantum computing must come from interactions among the qubits – so we should be looking at how many of the qubits can interact with one another at a time, how long these interactions take, and how reliable they are. In addition to this, we also need to know how long the qubits themselves can survive. Today’s quantum computers are very imperfect, and even small fluctuations in the environment (such as tiny, stray electric fields) can cause qubits to lose their information – a phenomenon known as “decoherence”. (What’s really important is the ratio of the qubit interaction time to the qubit lifetime, as this gives a rough idea of how many interactions we can reliably perform before decoherence destroys our quantum information. But this is a topic for another post.)
So what does it mean to say that qubits interact with each other? There’s not really a good analogy here to classical computers, since “bits” aren’t really objects, but are typically just electrical signals that flow freely along wires. In a quantum computer, however, a qubit is typically a real, physical object of some kind – for example, a single atom, a single defect in some host material, or a very tiny superconducting circuit. This means that if you have some number of qubits, they have to be physically arranged in some way – often either in a one-dimensional chain or in a two-dimensional grid – and the control system for the quantum computer must be able to very precisely control the state of each individual qubit, as well as turn “on” and “off” the interactions between various qubits. This ability to control interactions is often called the “connectivity” of the quantum computer. Depending on the type of qubit being used, the quantum computer may implement “nearest-neighbor” connectivity, where each qubit is able to interact only with those that are sitting adjacent to it in the 1-D or 2-D layout; “all-to-all” connectivity, where each qubit is able to interact with any other qubit in the system; or something in between.
Connectivity is important because it determines how efficiently we can run quantum algorithms, which typically require some complex series of interactions among all of the qubits in the device. If the qubits have all-to-all connectivity, these interactions can be implemented directly; but if the connectivity is limited (e.g., nearest-neighbor), then implementing an interaction between two qubits that are physically distant actually requires several interactions with intermediary qubits in order to achieve the desired effect. And because, as discussed above, the number of interactions we can run is limited by the qubit interaction time and the qubit lifetime, an increase in the required number of physical qubit interactions due to limited connectivity can significantly hinder the complexity of the quantum algorithms we can successfully run on the device.
So what’s the right way to compare quantum computers?
This doesn’t have a cut-and-dried answer, but a meaningful comparison certainly needs to take into account all of these variables – qubit count, qubit connectivity, qubit interaction time, and qubit lifetime. One recent attempt at such a metric is known as “quantum volume”, introduced by several researchers at IBM. This attempts to assign a numerical value to a quantum computer that, very loosely, indicates the maximum number of qubits which can all successfully interact with one another and maintain a high probability of producing a correct result. It’s a bit clunky, and certainly less headline-friendly than a simple qubit count, but at least it’s a good-faith effort to capture the full picture. If you’d like to read more about this and other metrics, there’s a recent article in Science that describes some of the various techniques that companies and universities have been using: “How to evaluate computers that don’t quite exist.”
(In the longer term, when we have fault-tolerant quantum computers enabled by quantum error correction, we will likely group large sets of physical qubits together into “logical qubits”, which automatically maintain their quantum state and are robust to errors. At that time, we will in fact care much more about logical qubit count than physical qubit count. But, again, this is a topic for another day.)
All this is to say: Just as we can’t judge the performance of a modern CPU solely by its clock speed, there is far more to understanding the performance of today’s quantum computers than simply the number of qubits. We must compare quantum computers based on their performance on the algorithms that we care about.